An Approach to Pipeline Testing
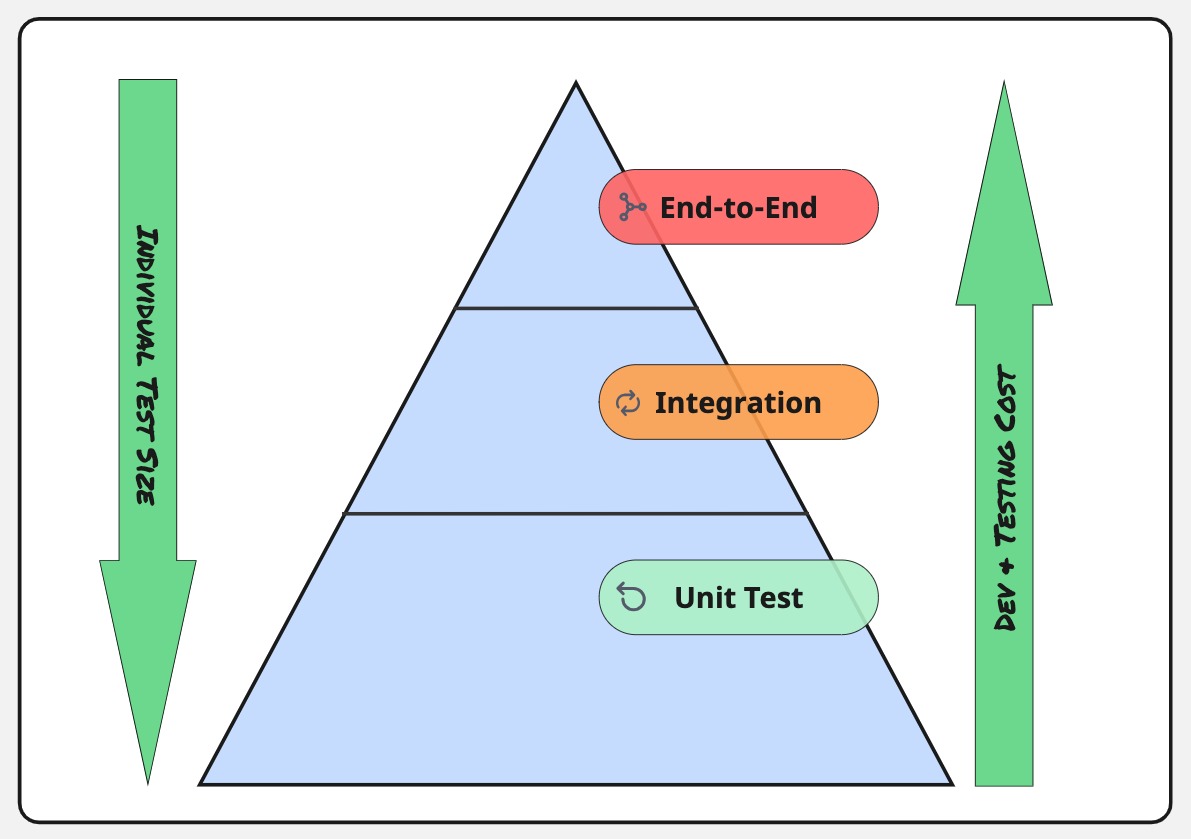
Data teams can learn a lot from software engineering. The same pyramid that guides unit, integration, and end-to-end testing for code also provides a blueprint for building confidence in your data pipelines
The Testing Pyramid in Context¶
A timeless concept
The testing pyramid emphasizes many small, fast tests at the base and fewer, broader, slower tests at the top.
The higher you go, the more complete—but also more expensive—the validation.
In software, this hierarchy keeps feedback fast and cost predictable.
In data engineering, the same principle applies: validate early, cheaply, and continuously.
Unit Tests — Verifying Pipeline Logic¶
At the base of the pyramid are unit tests, the fastest and cheapest layer.
For data pipelines, a unit test validates a single transformation or SQL model in isolation.
Running this query in a QA or test schema lets you catch:
- Syntax or logic errors (
CASE/JOINissues) - Incorrect column references
- Incorrect variable references
- Null or duplicate handling problems
These tests should be lightweight and automated on every deploy—your first safety net.
Integration Tests — Validating the Flow¶
Integration tests ensure that multiple components—API connectors, transformations, loads—work together correctly.
Typical examples:
- Run a connector to fetch sample API data and push into staging tables
- Execute downstream transformations to confirm joins and type consistency
- Validate that expected records flow from raw → processed → analytics layers
Integration tests often run in a staging environment, where mock data or limited real data can safely move through the pipeline.
Check completeness after load
A mismatch signals an integration issue, not just SQL logic error.End-to-End (E2E) Tests — Trusting the Whole System¶
At the top of the pyramid are end-to-end tests—broader, slower, and more costly but essential for production confidence.
In a pipeline context, E2E tests might:
- Run the entire pipeline using a copy of production data
- Compare results against previous successful runs (row counts, key metrics, summaries)
- Validate external system interactions (e.g., posting results via API)
- Confirm that pipeline orchestration, retries, and notifications all behave as expected
Mind the trade-off
E2E tests take longer and require more resources, but they’re your final line of defense before deployment.
Putting It Together — A Balanced Testing Strategy¶
| Layer | Scope | Runs In | Frequency | Purpose |
|---|---|---|---|---|
| Unit | Single SQL or transformation | QA / Test schema | Every change | Catch logic & syntax errors |
| Integration | Connected pipeline components | Staging | On deploy | Validate data flow & interfaces |
| E2E | Full pipeline | Copy of production | Scheduled / pre-release | Ensure consistency & system health |
A healthy testing pyramid isn’t about quantity—it’s about balance: lots of fast, automated checks, and a few deep ones that ensure trust.
The Takeaway¶
By structuring your pipeline testing like software engineers structure code testing, you:
- Catch errors earlier
- Reduce re-run costs
- Improve data reliability
- Ship changes confidently
At Data-Conductor, we’re baking these principles directly into how pipelines are orchestrated—so testing becomes a built-in habit, not an afterthought.
Good testing, like good pipelines, is all about flow: small checks leading to smooth delivery.
🧩 Keywords¶
data testing, pipeline validation, e2e, integration testing, unit tests, data orchestration